Today I'm going to write about something quite different than anything I've done yet. Most of my articles to date have been very specific tutorials on how to accomplish something in a given language or framework. Today I'm going more conceptual and I'll explain my thought process behind how I built a web app from start to finish. This article specifically will cover a lot of the brainstorming, discovery, and project planning, whereas the others will cover specific features and how they were implemented.
Introducing GuardianForge
Over the last few months, I've been building a web app called GuardianForge, which acts as something of a social media for players of the game Destiny 2. It allows users to create snapshots of their current equipment in the game and share with other players. The equipment you have on your character in the game affects how the game plays, and can make activities either harder or easier depending on how you setup your loadout.
Build crafting in Destiny seems to be on the rise, and one thing I personally do before going into high level activities is ask around to find the best items to have equipped. A lot of Destiny content creators also produce build video for these activities which describe the items you should have equipped. Here is a small sample of one of my favorite creators Castle explaining a build in the game and how it works.
The problem is there are so many combinations I often cant remember much of the equipment they suggest, so one day I thought "Wouldn't it be nice if there was a convenient way to share an entire loadout using just a link?"
And that thought was the beginning of GuardianForge.
GuardianForge is still a work in progress, but the basic gist is;
- Find a players character & view the loadout.
- Create a build snapshot containing all the equipment, along with optional notes.
- Share the unique link for that build to...anyone.
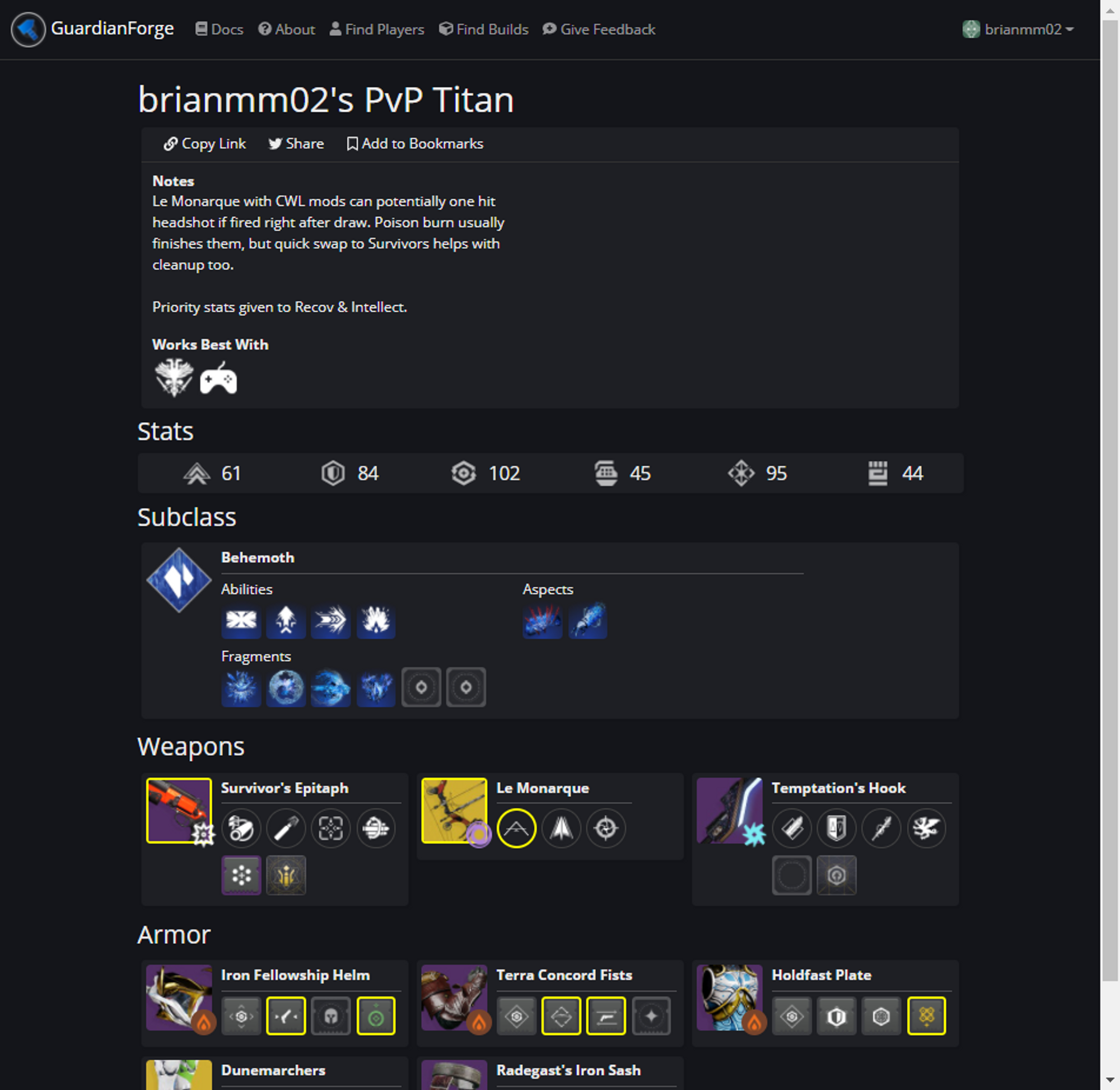
https://guardianforge.net/build/226dee1e-6b03-4074-8de9-576f60443e7e
Exploring The Destiny API
Before I even start writing any code or planning infrastructure, I always explore APIs to see if my idea is even possible with what's provided. Bungie has a decently documented API located at https://bungie-net.github.io/multi/index.html so that's where I started. In order to access it, I first needed to register an application in their developer portal.
So the API call that seemed to give me some of the data I wanted is the GET Character API. There were a few pieces of info I needed first, the membershipId and membershipType. After doing some digging, I found that I was able to find this info on the GET User API.
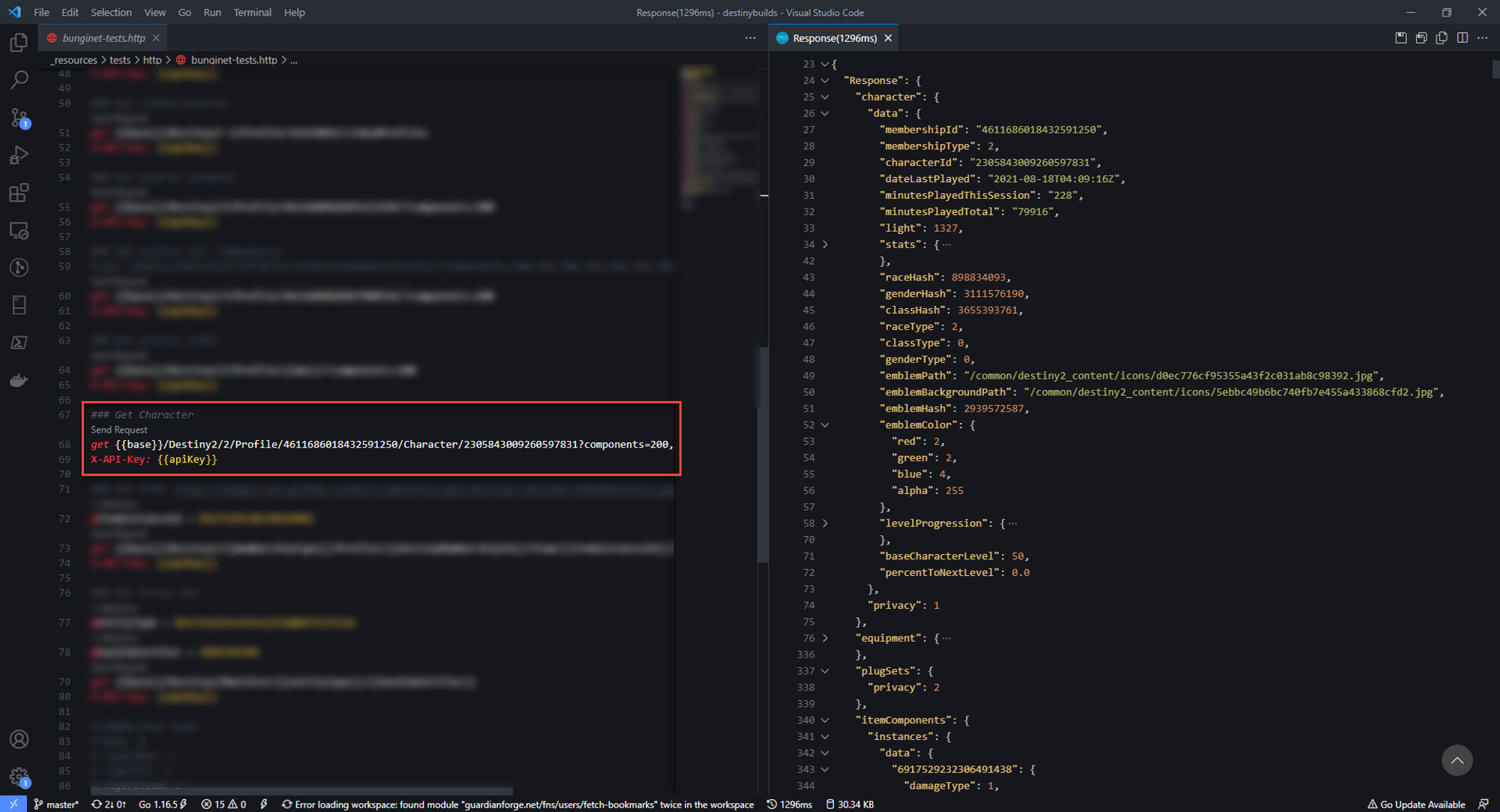
Before I could call GET User, I needed the unique ID for that user in Bungie's system. I traced that back to the GET SearchUsers call, which let me search by username.
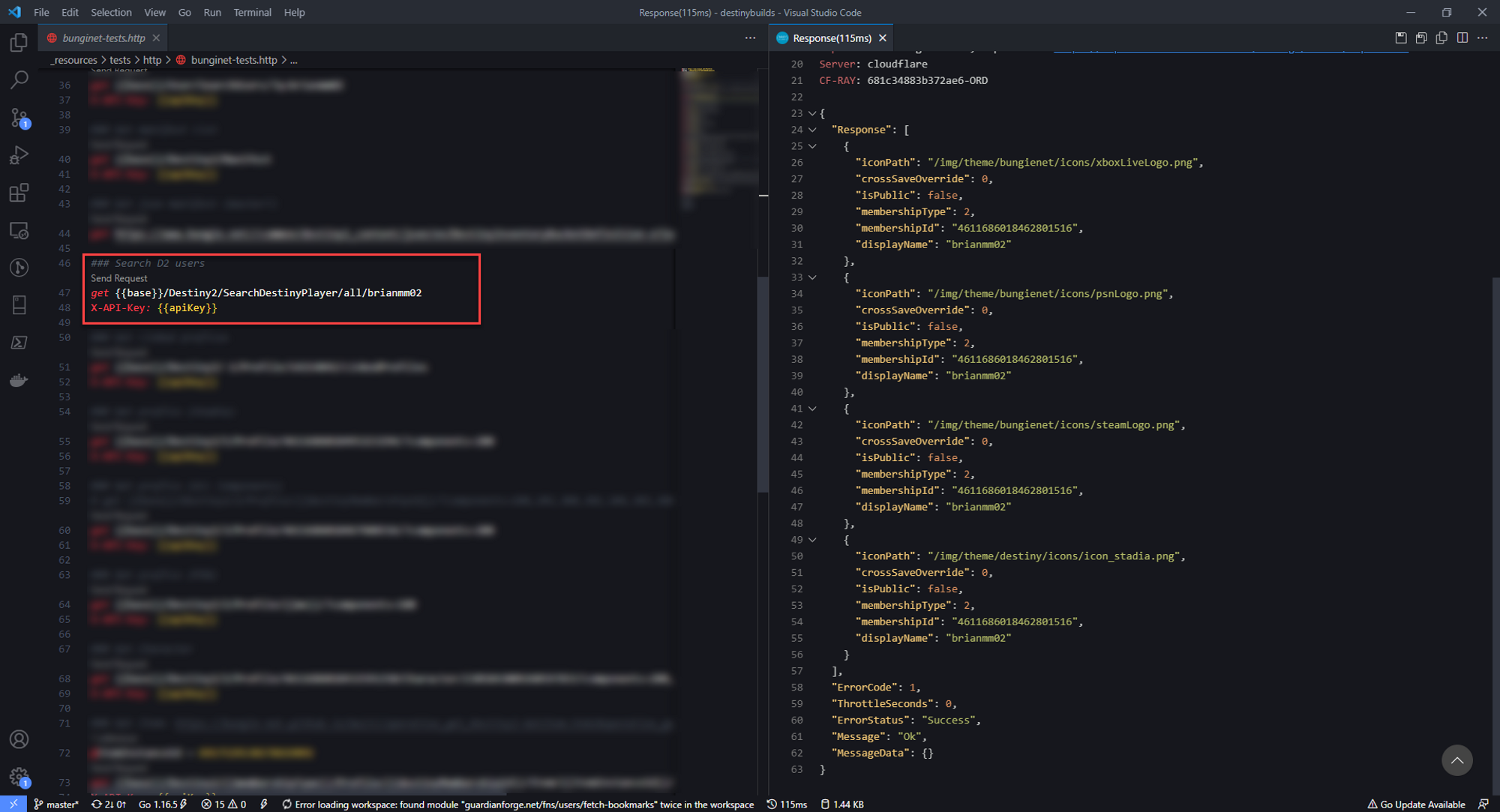
Perfect, now back to the GET Character API. Bungie's API uses a query parameter called components that lets you request only the info you need from that specific call. Unfortunately I didn't know what each of these components returned (and although it was documented, it still didn't mean much to me at the time).
Exploring How Other Apps Work
Its about here that I started exploring other third party Destiny apps to see how they did it. So I reviewed one of these app's network requests using the Chrome dev tools' Network tab. The numbers at the end all look weird, but that's because they are URL Encoded (meaning they are changed to be more compatible with URLs). You can swap the %2C with a , and it looks more like 100,101,103...
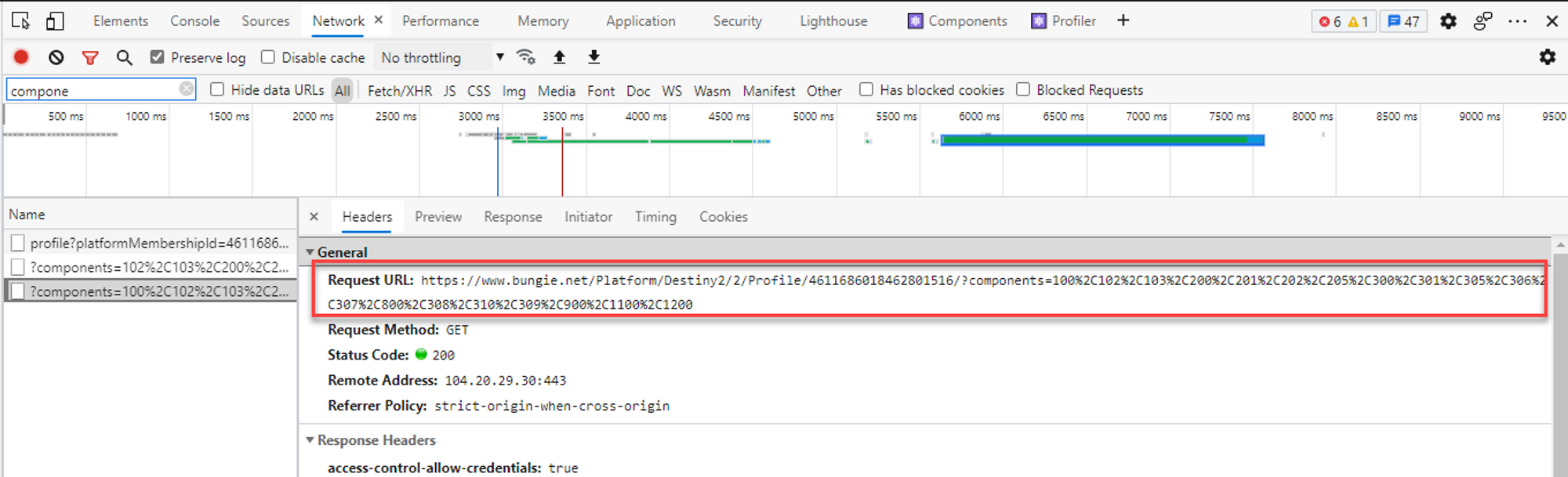
So I can match up those numbers with the API documentation to figure out what each really does.
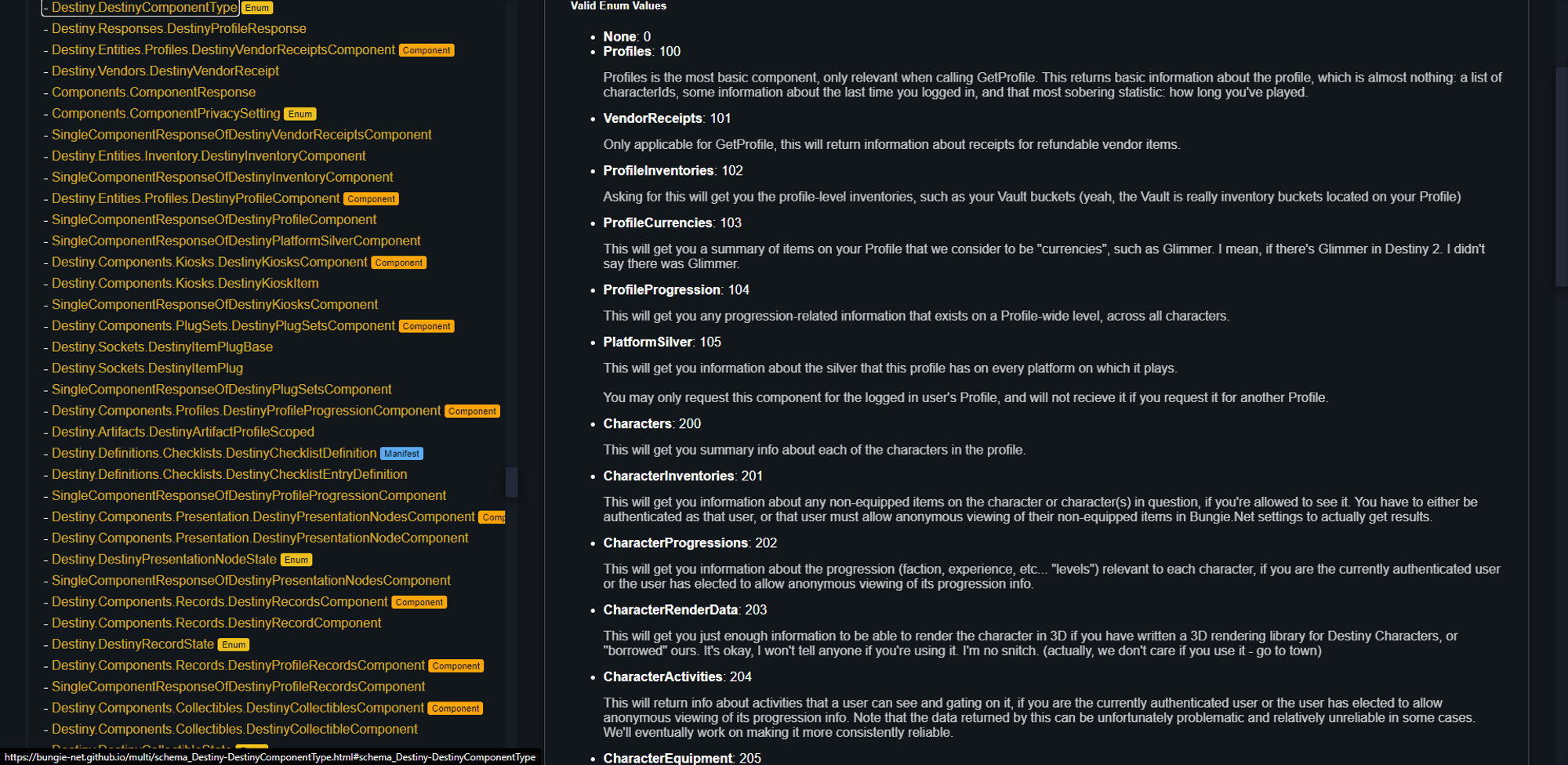
So now Ive got a list of components that I needed to request. Requesting it resulted in a rather large response and a whole lot of data that meant very little to me. I had no idea how to decipher it.
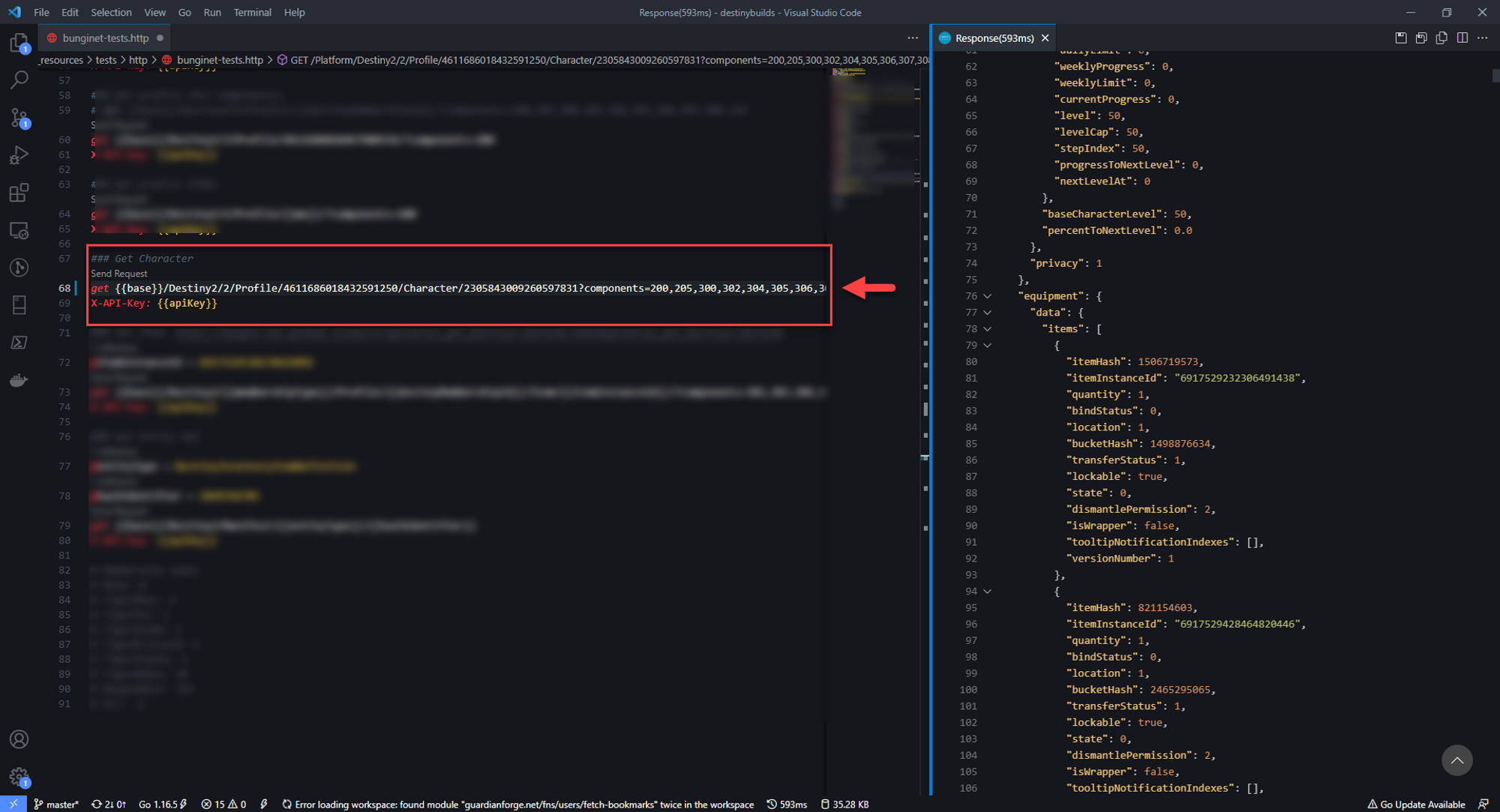
The Destiny Manifest
Now Ive used third party Destiny apps for a number of years and I've always heard about the "Manifest" that is downloaded whenever you use one of these apps. I saw there was a call to GET Manifest in the API docs, so I ran that call to see what came back. To my surprise, it was a bunch of URLs along with some other metadata.
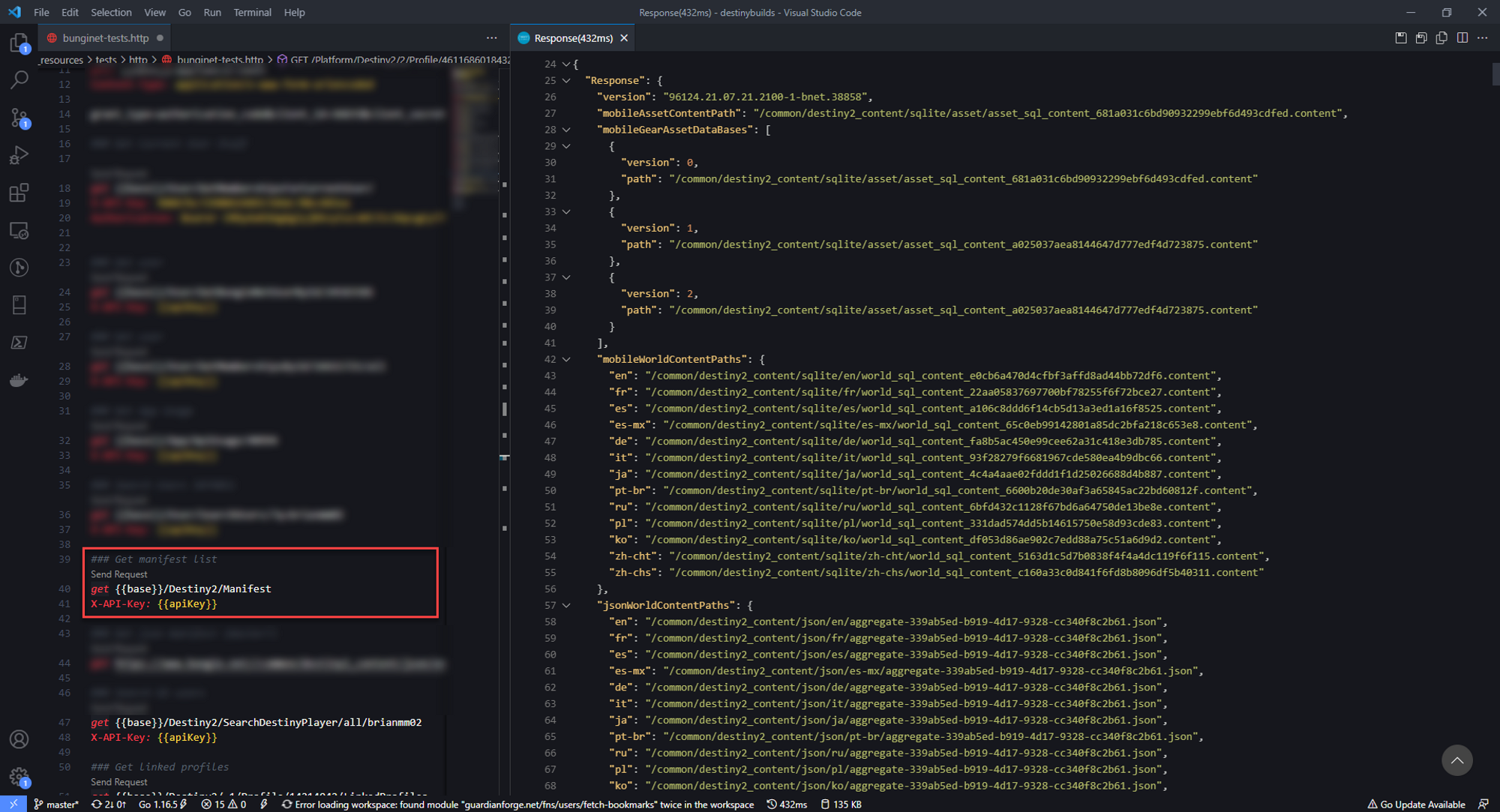
Attempting to grab one of these URLs resulted in a key/value JSON file. The keys in this dataset actually correspond to some of the data in the GET Character response. The Manifest is essentially a database with a massive amount of info on everything in the game.
Now these files can be rather large (one of the largest I use is about 60MB) and attempting to view them in the browser or VS Code resulted in a crash every time. Its just too much data to render in those apps. So I did a bit of digging and discovered Dadroit JSON Viewer.
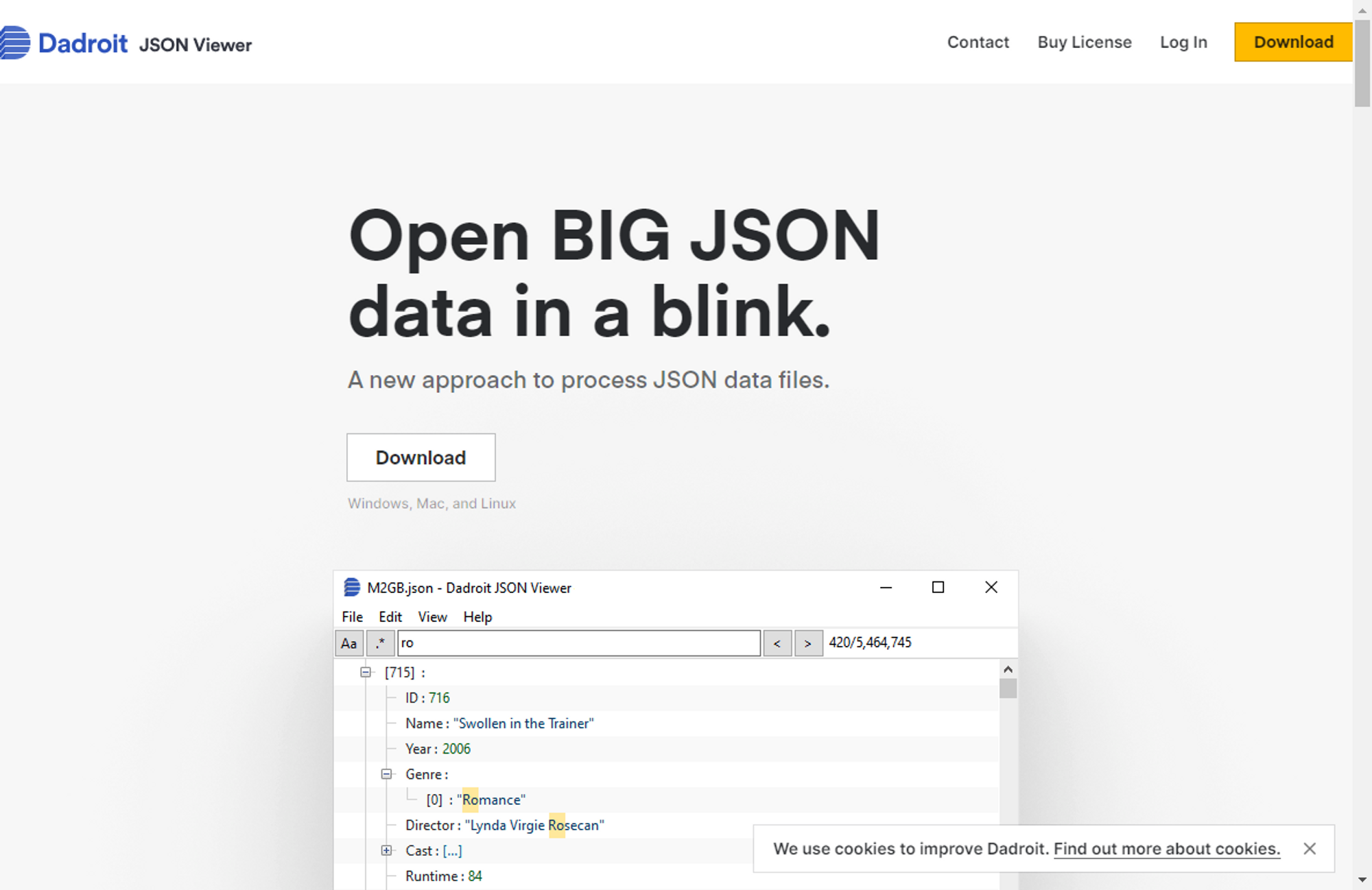
Using Dadroit, I was able to search the entire manifest for the various hash values to figure out in which manifest file, and where, the info I needed was. If there was info I didn't have a hash for, I also leveraged some of the text found in game to discover the location of that info.
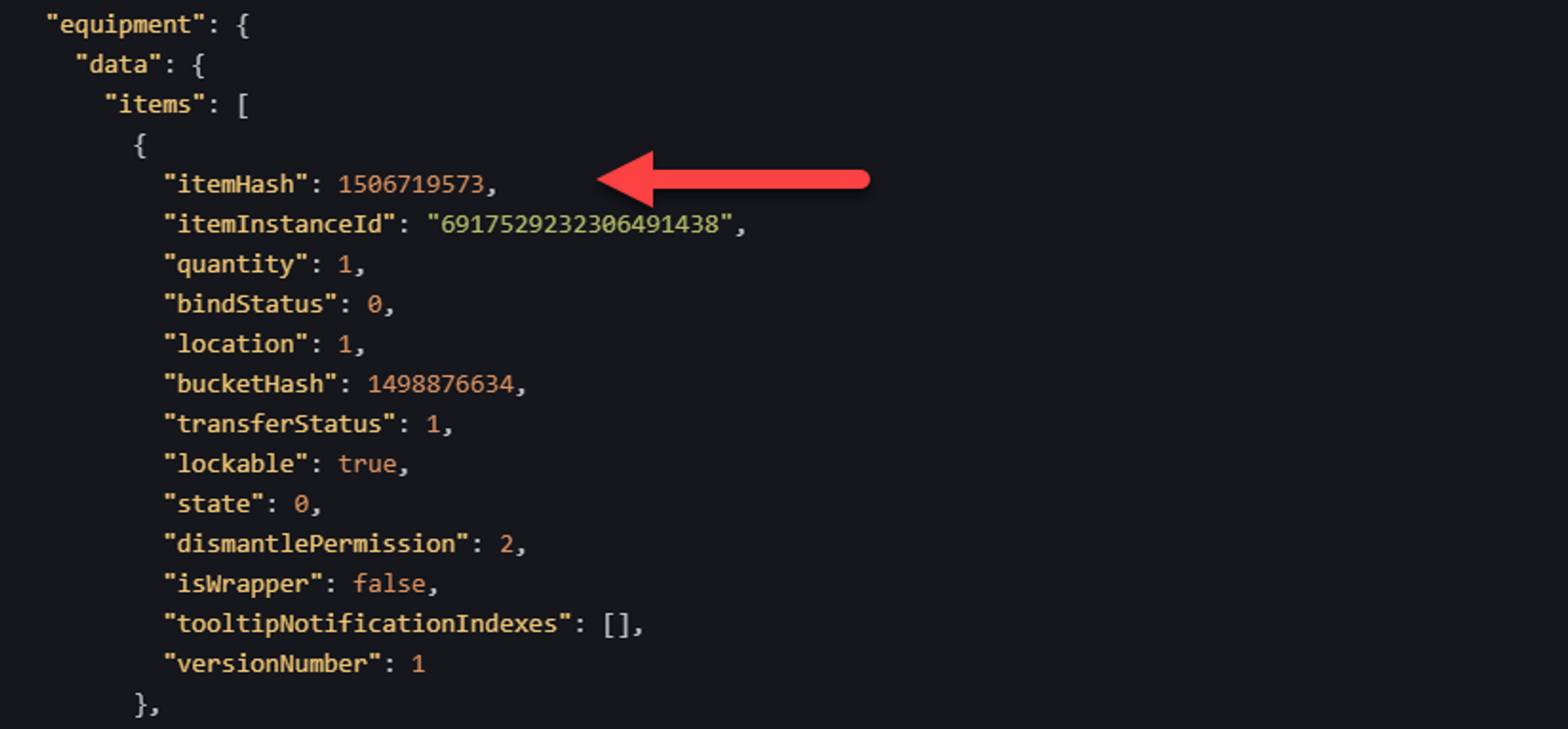
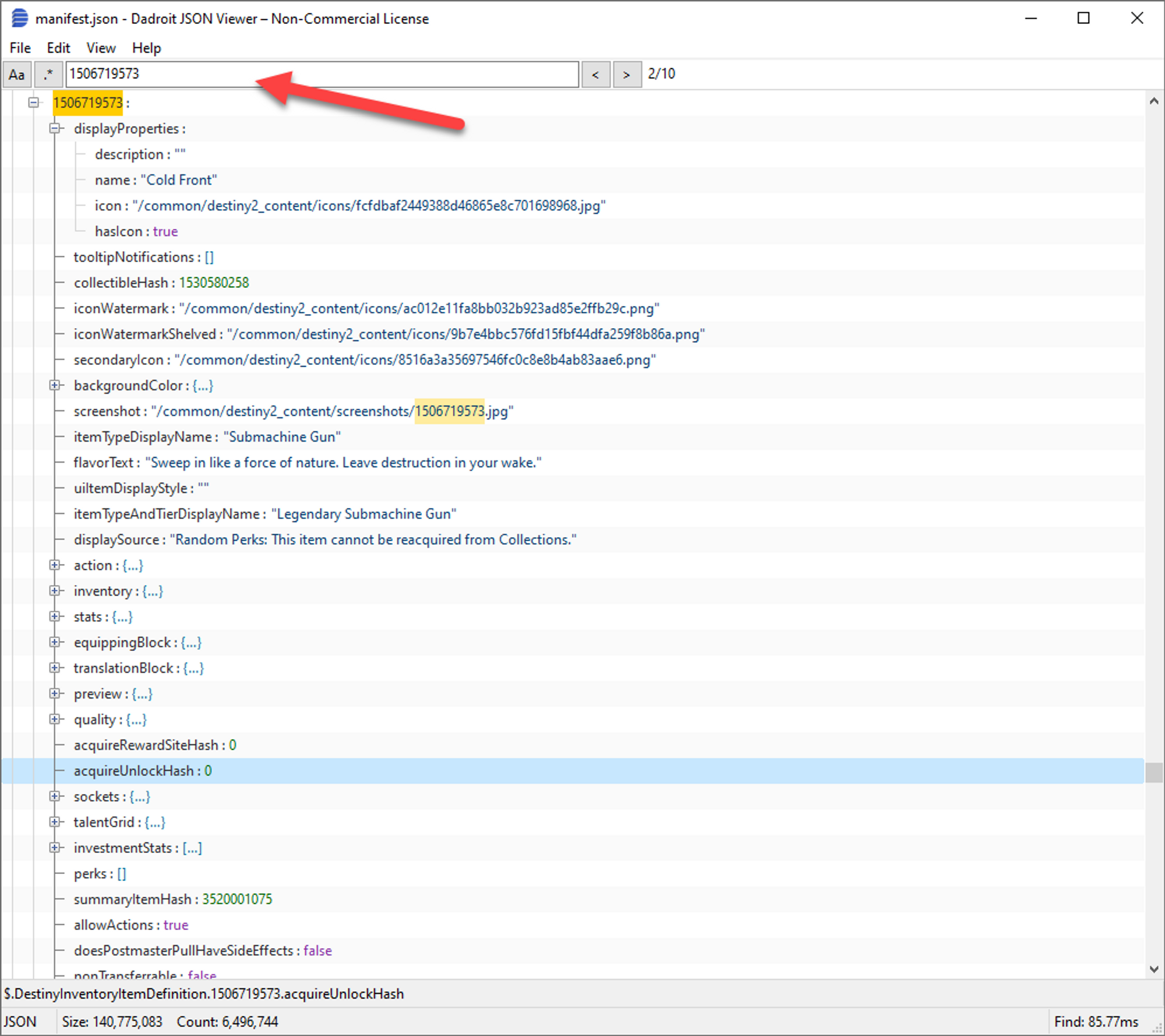
So after many hours of tracing data around the manifest, I realized that I could totally build an app that does what I needed it to.
Infrastructure Planning
Now my original goal with this project was to build something on AWS using as many services as I can to make this thing fly. I generally use these projects as opportunities to do something new, and this was no exception.
So whenever I approach a new app, I split it all up into three categories;
- Front end: Where will the user get access to the app?
- Back end: Where will I make API requests to?
- Storage: Where will all the data be stored?
I also break out the things I want to user to do;
- Search for Destiny users & select any of their characters
- Create a build, adding notes and other meta info
- View & share builds
And here is ultimately how the project was broken up:
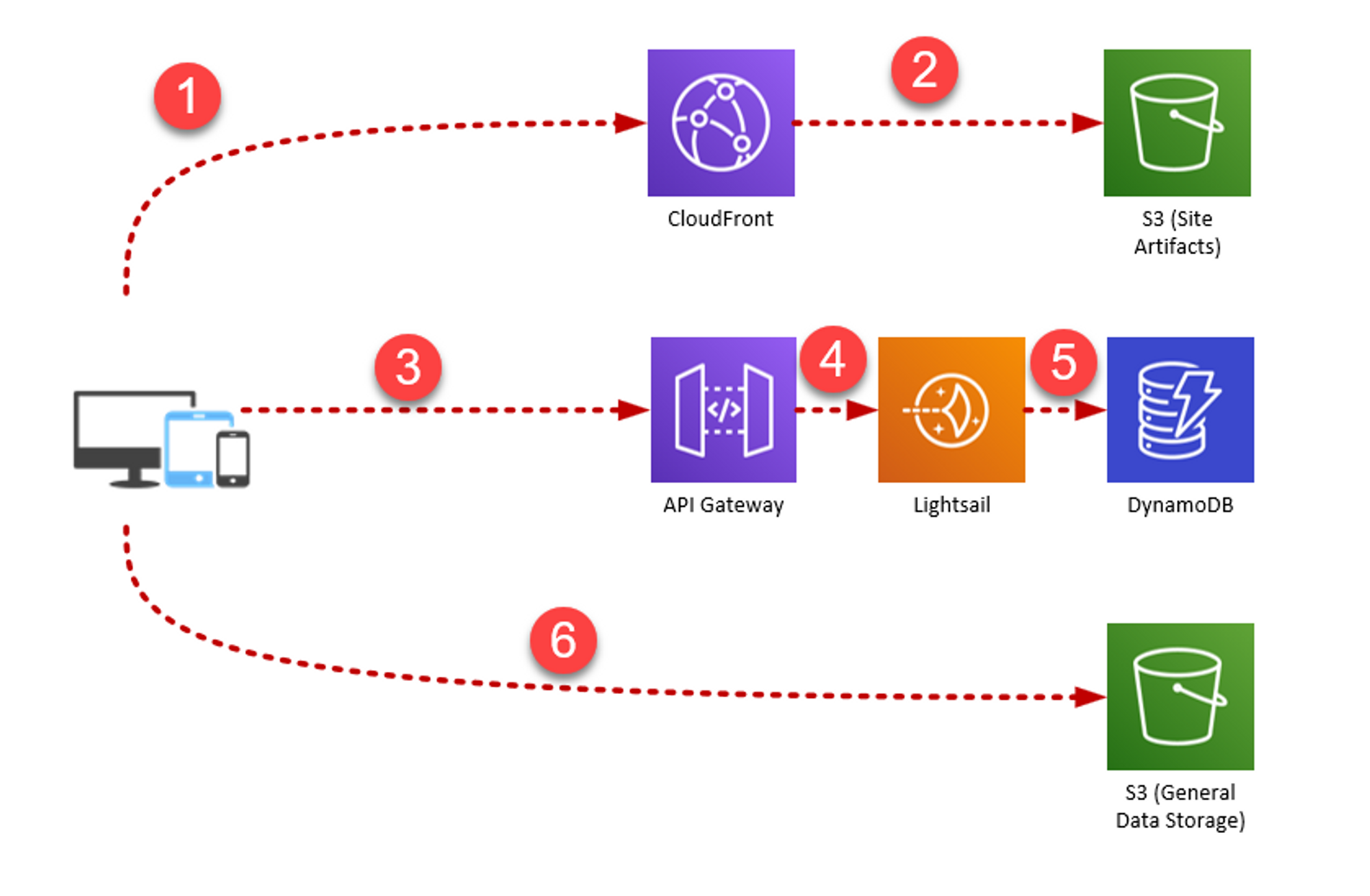
- When first hits guardianforge.net, they will access a CloudFront CDN instance which returns the Vue application to the user.
- The built Vue app is stored in an S3 bucket, where CloudFront Accesses it.
- Requests to the API go to API Gateway.
- API Gateway forwards those requests to a Lightsail VM, where the main API code is running.
- The API accesses relevant data from a DynamoDB table.
- When a build page is loaded, the Vue app will request the raw JSON file from a separate S3 bucket directly.
Read on for more info on how each of these components work and how they are used in GuardianForge.

DynamoDB
DynamoDB is a NoSQL solution in AWS. I wanted to use GuardianForge as an opportunity to get practice modelling a schema for Dynamo. The main idea was to use Dynamo as more of an index than a full database. I would store build summaries as stubs of the real data. This reduces the amount of data stored in Dynamo, which reduces cost on both storage and egress (data leaving AWS) charges.
Dynamo is VERY fast if the schema is designed properly. I'll be covering my schema design process in a later entry in this series.

S3
I decided to use AWS S3, which is their solution for storing unstructured data (think like files & folders). I'm using it for two functions.
The first is storing the front end Vue.js application files. S3 has static web hosting feature on its own, but in order to use my own domain name, I ended up connecting to it via a CloudFront CDN Instance (more on that in a moment).
The second is the actual build data. Each build has a corresponding JSON file that's stored in S3 that contains all of the necessary build data to render it in the Vue app. Now why wouldn't I just store this in Dynamo? Well from a cost perspective, Dynamo generally charges more for storage and less for transmitting data, whereas S3 is the opposite.
In general, the actual build files will not be hit too frequently (unless one gets really popular), so Id rather pay less for storing this data. In either case, I could put them behind the same CDN as the application files to increase performance and decrease actual hits to the file.

CloudFront CDN
Now in the previous section, I mentioned putting the app files behind CloudFront CDN. A CDN is a service that distributes static pages to various endpoints throughout the world. This results in decreased latency when a user hits those pages.
Using the combination of CloudFront & S3, I can not only optimize performance for my users, but also add my own domain name & acquire a free SSL certificate using Amazon Certificate Manager (ACM).
I can also setup some pretty fancy routing rules, which I end up doing when implementing social opengraph meta info. More on that in a later entry.

Lightsail
Lightsail was one of those new services I wanted to try out. From my understanding, it lets you setup databases, servers, and containers at a fixed price in AWS. I'd worked with EC2, which is the server platform in AWS, so this was quote similar.
Essentially I just had a Linux server that would run the API written in Go. Go was also another thing I wanted out of this project. I hadn't built a real world project with Go up 'til this point. When a Go app is compiled, it produces a native executable binary that can run on the same platform it was built on. So I ended up writing a Systemd Unit file to manage & run the service when the server starts. This was also something I hadn't done before, so it was a neat learning experience.

API Gateway
Now API Gateway was a pretty late addition to my infrastructure. The main reason (and its not a good one) was to add SSL to my API. This was admittedly just a band-aid instead of a permanent solution. I wanted to buy myself some time to figure out how I wanted to secure the API properly.
API Gateway acts as an API management platform in AWS. So you get one URL and you can route requests to other URLs or services within AWS. I actually decided to leave API Gateway in the diagram because it becomes much more important later on.
Code Storage, Project Management & Continuous Deployment
The final pieces of this puzzle are less about the infrastructure and more about managing things. While the obvious thought would be GitHub, I've been a huge fan of Azure DevOps for years. Name aside, it actually has very little to do with Azure.
Ultimately this is personal preference. I like the UI in Azure DevOps, the more advanced project management tools, and the better ability to create pipelines for deploying and managing builds.
Azure DevOps has built in support for sprints & breaking down work items into features or epics if needed.
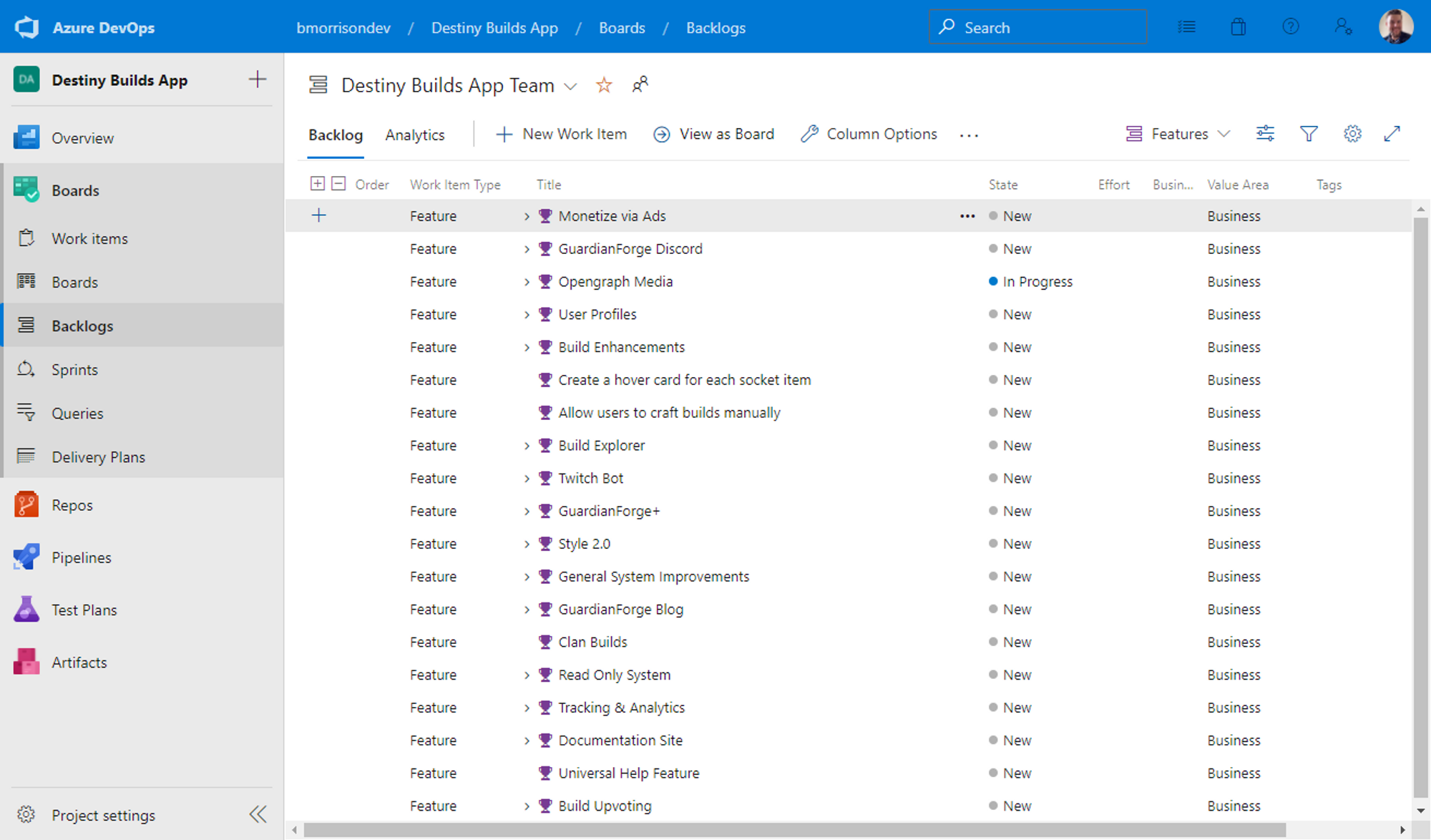
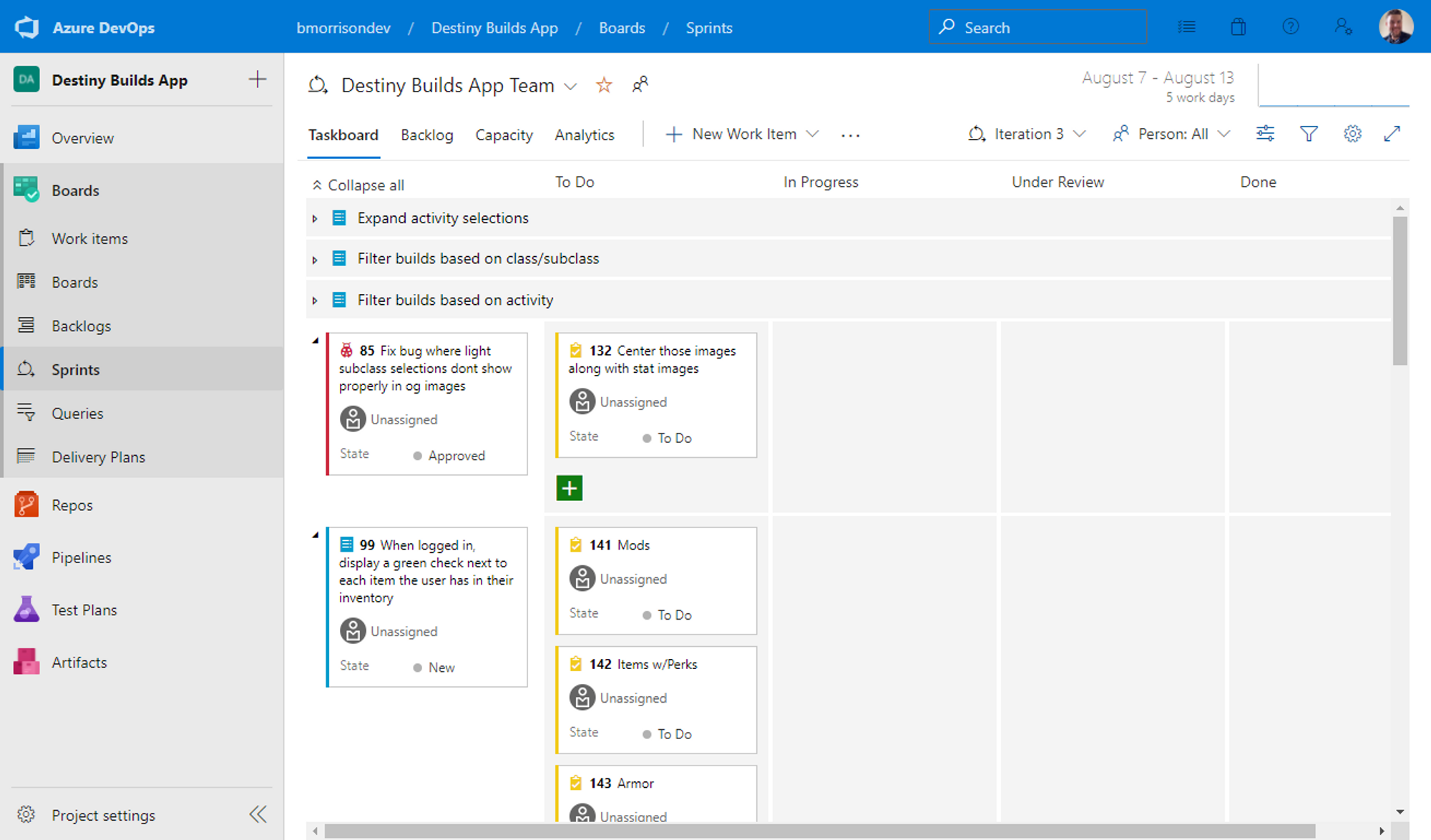
Now if I want to somehow link a commit to a work item, all I have to do is include the task number in the commit message and I can trace my comments to whatever tasks I have.
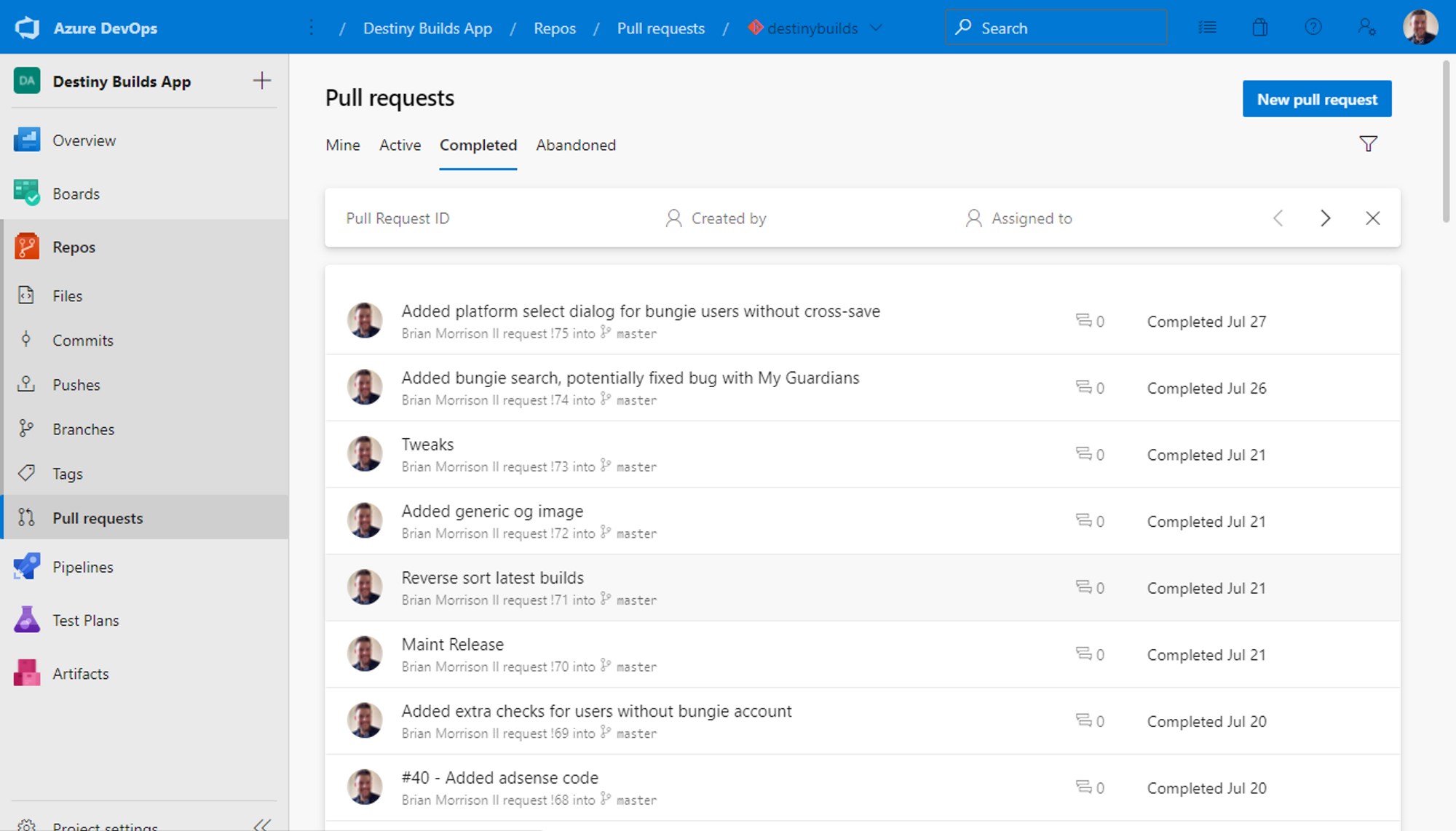
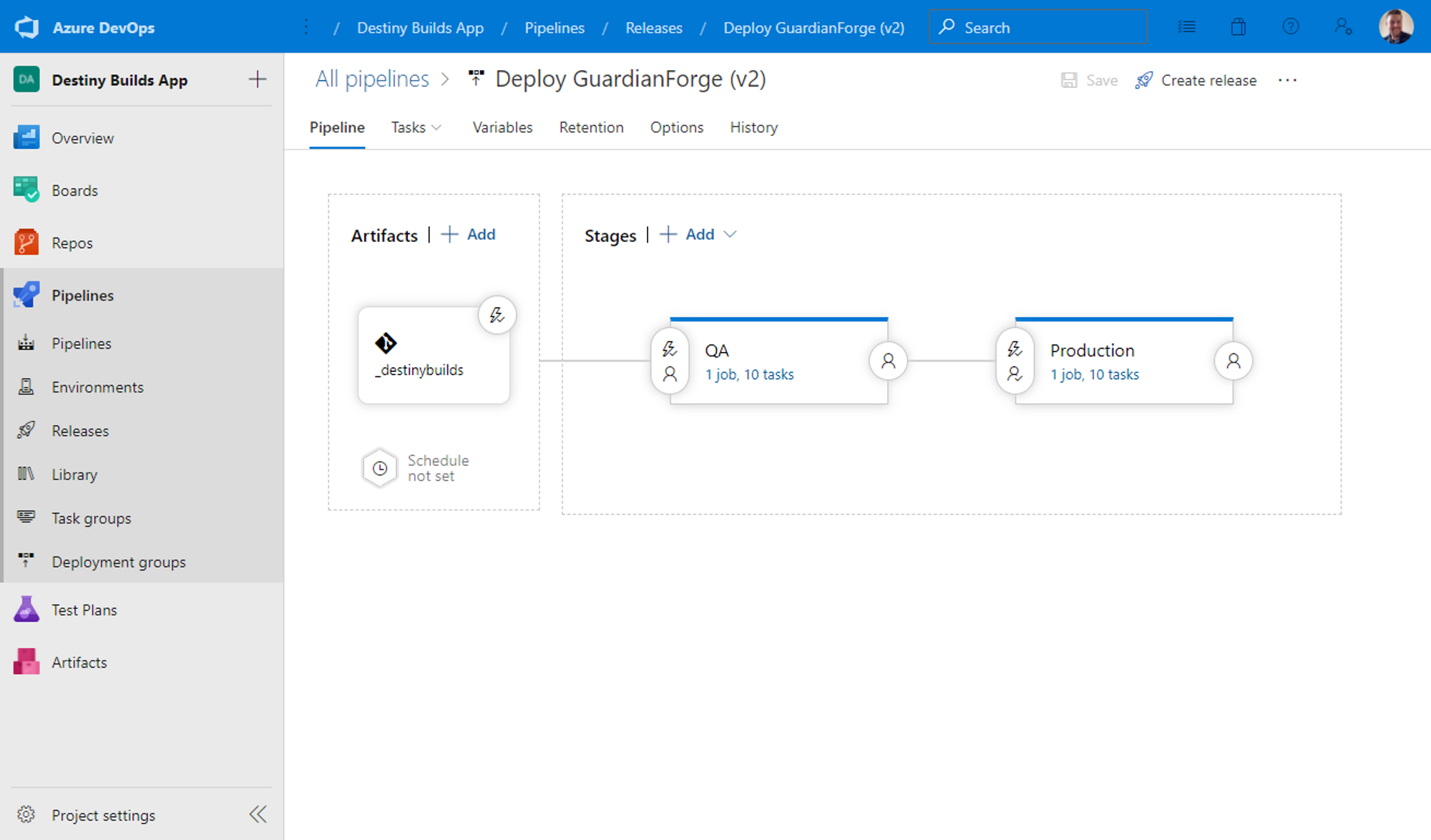
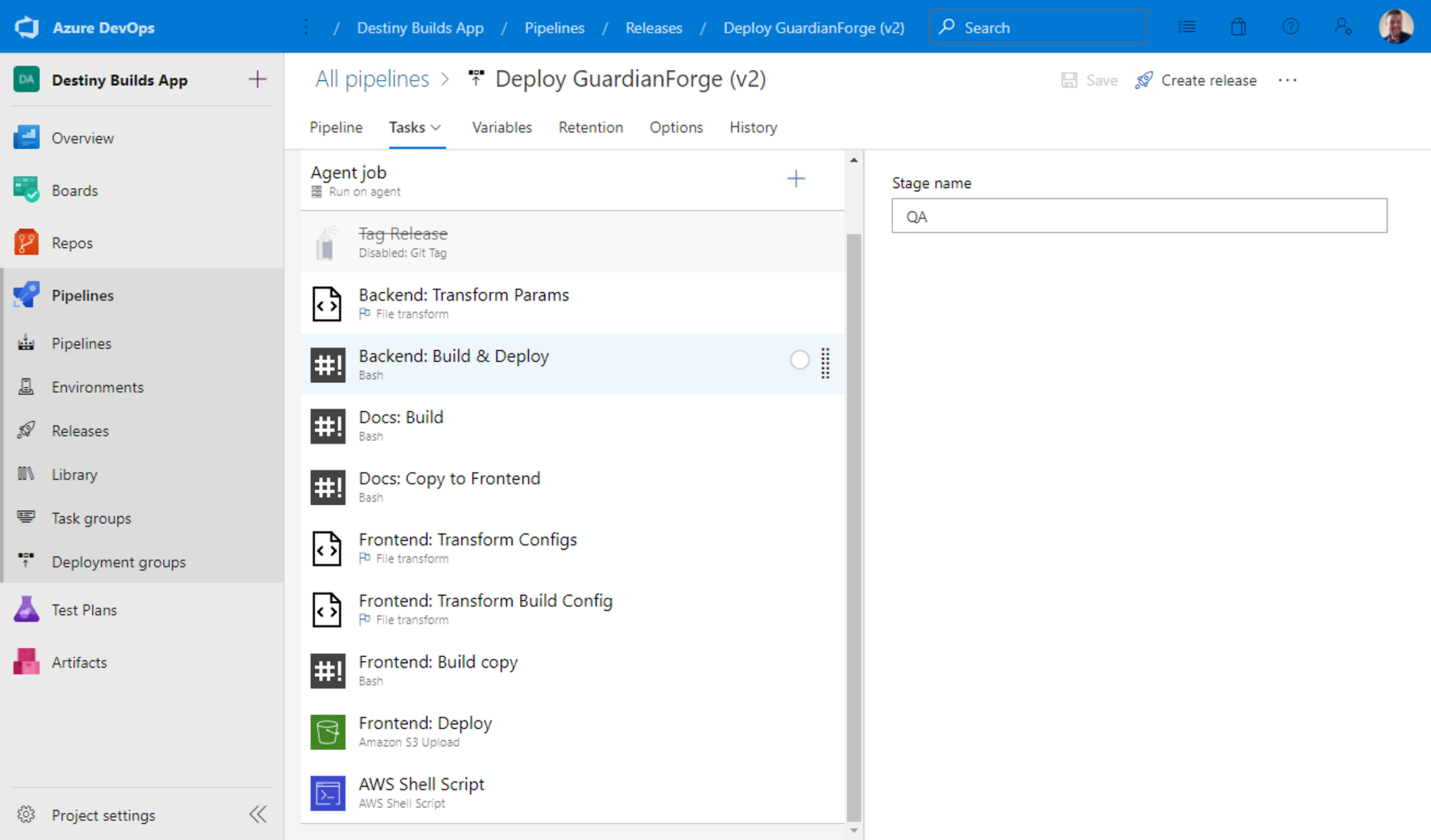
Finally I can control my builds/deployments using their Pipelines feature. Pipelines is essentially a glorified task runner. I can pick from predefined step templates, or just write my own scripts to run at certain parts of the process (which I generally lean towards).
Looking Ahead
Working on GuardianForge has helped me learn a bunch of interesting little tidbits that I didn't know before. I plan to identify some of the features of GuardianForge and create articles & videos on them, as well as overcoming some issues, in the near future. Happy coding!