
Last year I overhauled the UI for GuadianForge and a bug that has plagued it since was that editing builds broke. I stepped away from the project as I didn't have time but now that I’m back to actively working on it, I really wanted to understand what broke along the way. Spoiler alert: this was probably broken since I built the feature originally.
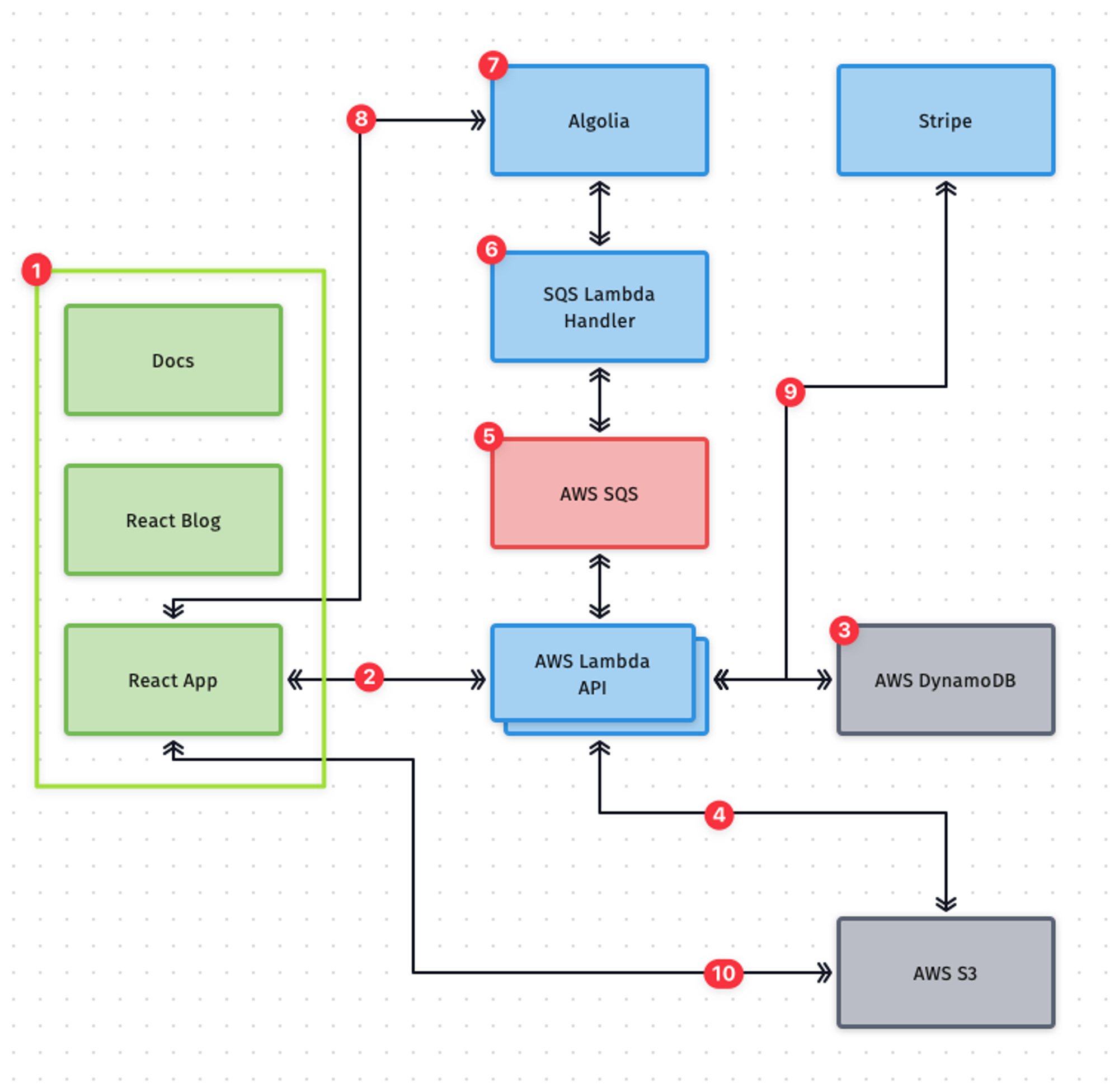
Before I dive into the debugging process, its worth understanding the GuardianForge architecture. It is an entirely serverless application on AWS built with a number of different services. The backend is predominantly AWS Lambda Functions, data is stored between DynamoDB and an S3 bucket, and the front end is a series of React apps hosted in S3 but served via CloudFront CDN. When a build is loaded, the front end actually downloads a JSON file from S3 directly to display the info.
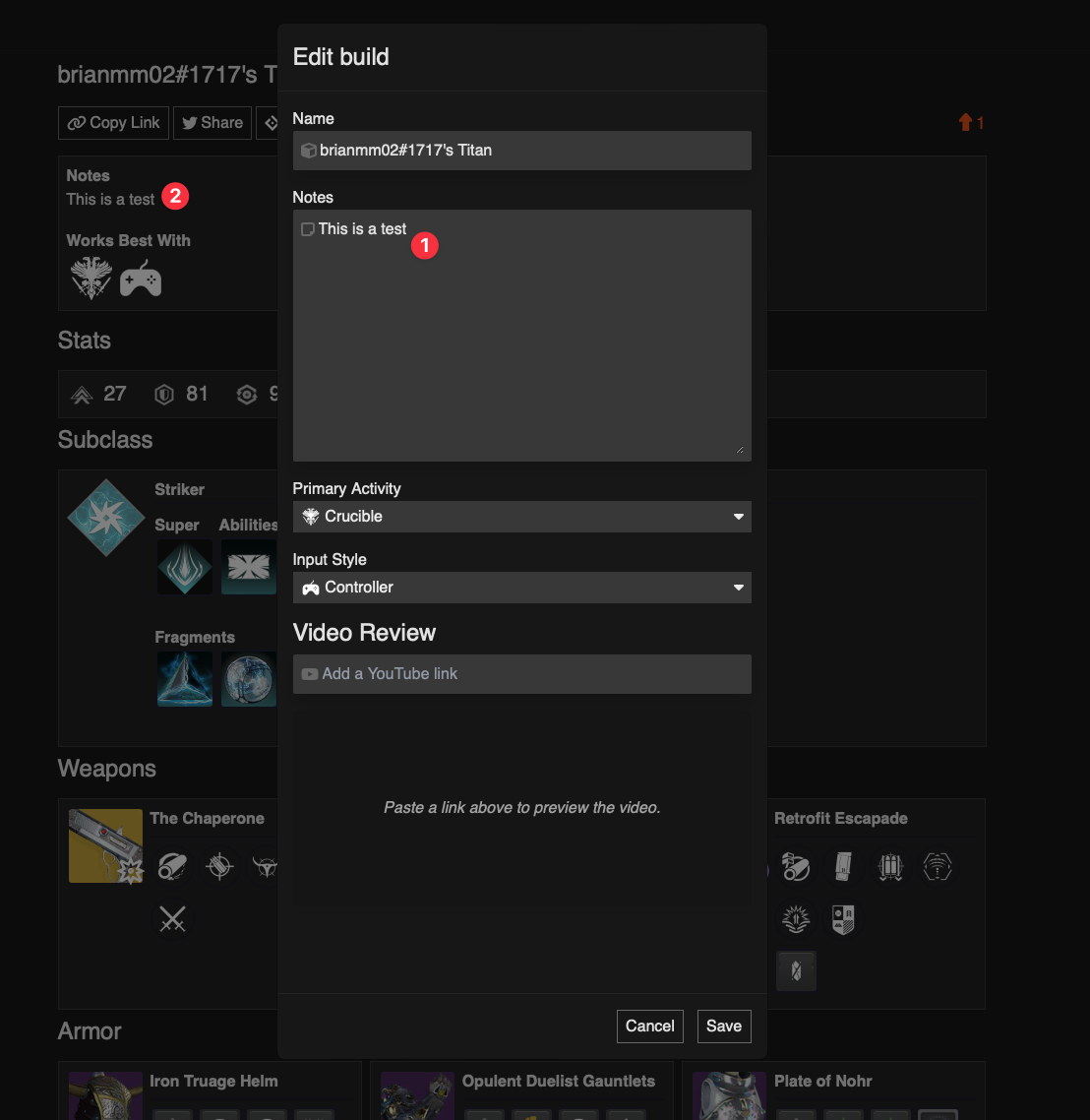
With all that said, there were two bugs that were causing this behavior. The first bug (and what I thought was the only bug) was relatively straightforward. In the edit form, I was updating calling the proper API endpoints to update the data but I wasn't actually updating the data displayed on the Builds page. For example, the screenshot below shows the Edit Build modal. Saving this form would send the API request, but wouldn't execute the callback to the parent view to update the Notes field on save.
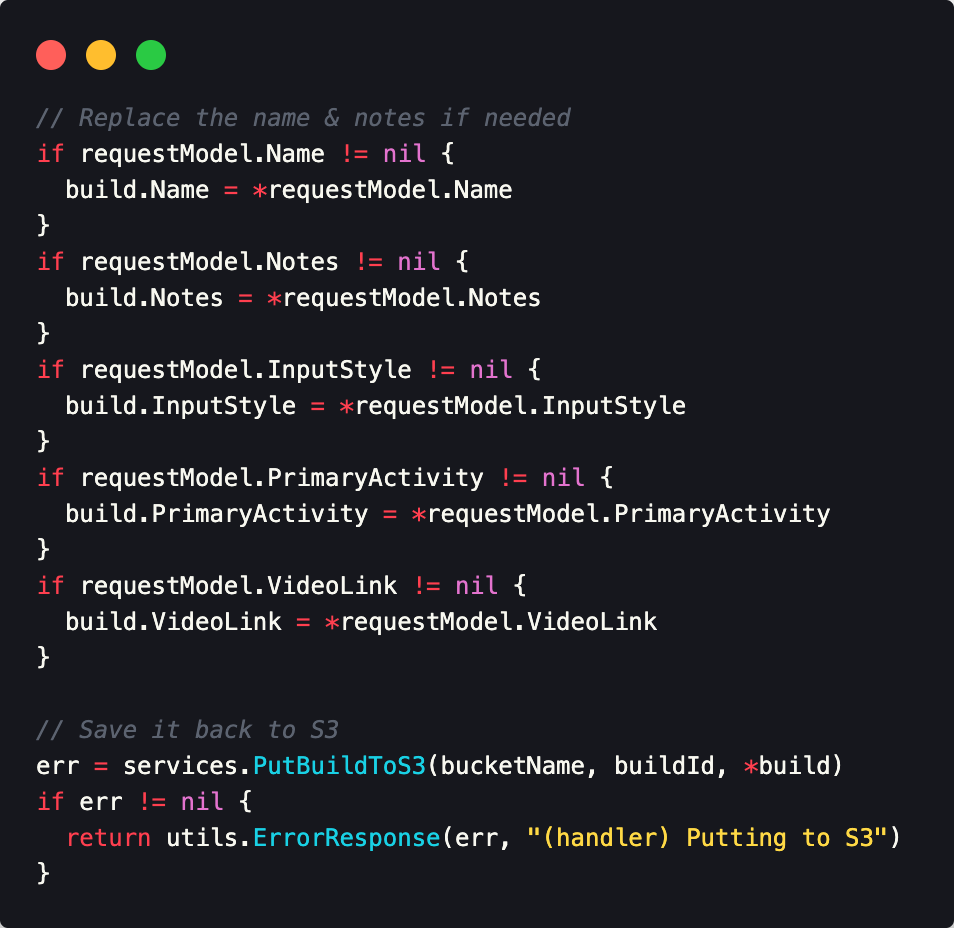
So I update the code to fix this and everything seems to be working properly, however refreshing the page would show the old values still, which was super confusing. I start by looking at the API code. Since I have build data stored in both Dynamo and S3, I had to figure out if one of them wasn't saving properly. I wrote some logging code to make sure values were updating properly and sure enough they were. Below is a snippet that updates the build data in S3.
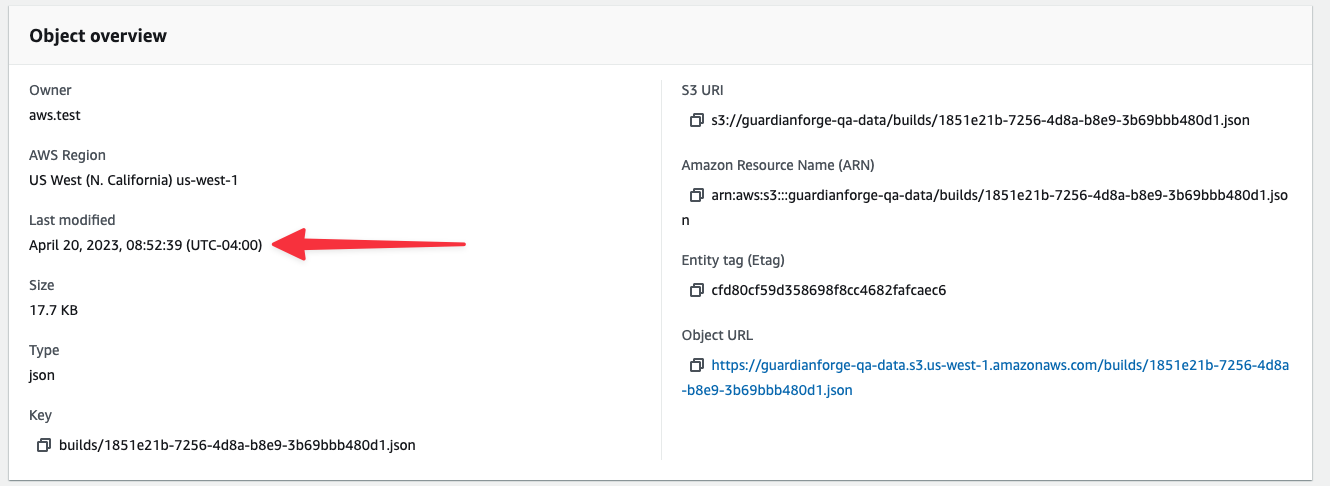
I logged into AWS to check the data in S3 to see if it was properly updating. Again, seemed to be updating properly. I don’t have a screen cap, but even rendering the JSON in VS Code showed the updated values!
Now I wanted to see the data that was actually being downloaded so I went to the Chrome dev tools to dig into the network request more and noticed this little message in the request headers:

There it is! Chrome was caching the JSON file and just displaying what was downloaded BEFORE the edits were made. Fixing this is actually pretty easy. All I had to do was add a query when the file was requested that had a different value each time. Using (new Date()).getTime() would guarantee that I’d get a unique value each time as it outputs a millisecond timestamp, so adding this into the request informed Chrome that it would need a new file each time!
